Lektion 8: Datahantering#
Moment: Datahantering
Nya begrepp: Modulerna csv, matplotlib
Arbetssätt: Arbeta gärna tillsammans med någon, men skriv egen kod. Diskutera med varandra! Du måste själva kunna förklara och diskutera din kod när du redovisar.
Uppskattad arbetstid: 8 timmar.
Redovisning: Obligatorisk redovisning av uppgifterna A och B enligt tiderna på kurssidan.
I. Importera data#
Data kan finnas i mängder av olika format, även när skaparen aktivt har
tänkt att de ska användas för vidare analys (.xls, .json, .txt,
…). Komma-separarerade värden (comma-separated values), .csv, är
ett enkelt, portabelt och populärt format för tabelldata. I Python finns
modulen csv som
kan användas med .csv-datafiler.
Läsa in CSV-data#
Om vi vill läsa in CSV-filer i ett Pythonskript kan vi använda modulen
csv tillsammans med det vi redan har sett om att hantera filer och
text. Tänk till exempel att vi har filen people.csv med följande
innehåll:
No, Name, country
1, Alex, USA
2, Erik, Sweden
3, Cheng, China
Då kan vi läsa in den med följande kod.
import csv
with open('people.csv', 'r') as csvFile:
reader = csv.reader(csvFile)
for row in reader:
print(row)
Koden ovan ger utskriften:
['No', ' Name', ' country']
['1', ' Alex', ' USA']
['2', ' Erik', ' Sweden']
['3', ' Cheng', ' China']
Här har vi använt csv.reader som ger oss ett itererbart objekt över
raderna i filen. Det finns fler
exempel i den
officiella Pythondokumentationen för csv-modulen.
Förbearbetning#
Det enklaste är att importera csv-data rakt av som en tabell (en lista där varje rad är en lista med kolumnvärdena). Det blir dock ofta ganska opraktiskt. Om vi vill hitta raden för ett visst land måste vi då gå igenom hela listan. Ofta vill man i stället kunna söka lätt och då blir lexikon lämpliga.
Obs! Det är vanligt att den första raden i en CSV-fil är rubriker i
stället för datainnehåll (så var det i people.csv ovan). Om man vet
vilka kolumner som finns vill man oftast bara ignorera rubrikraden.
Obligatorisk uppgift A#
Ladda ned filen CO2Emissions_filtered.csv. Du kan öppna den i en texteditor eller ett kalkylbladsprogram (som Excel, Numbers, Sheets) för att förstå strukturen på filen.
Obs! Om du öppnar filen i Excel är det viktigt att du inte klickar på spara i Excel. Excel kan då formatera om filen och ta bort vissa viktiga citationstecken. Om du vill kontrollera att filen fortfarande har rätt utseende kan du öppna den i en texteditor (t.ex. VS Code) och kontrollera att det näst sista landsnamnet är "Yemen, Rep.", inte Yemen, Rep.. Om filen är ändrats är det enklast att ladda hem en ny kopia och använda den istället.
När du
förstår hur filen är uppbyggd skriver du en funktion
load_csv(filename) som har filename som parameter och returnerar ett
lexikon med landskoder (skrivna med enbart gemener) som nyckel och
listan med koldioxidutsläpp per år som värde.
Tips! För att ditt program ska kunna läsa in filen CO2Emissions_filtered.csv är det enklast att du lägger filen i samma mapp som ditt Python-program. Om du använder VS Code behöver du sedan navigera till den mappen, t.ex. genom att klicka på ”Open Folder…” och sedan öppna den mappen. Alternativt kan du skriva hela filens sökväg.
Tips! Precis som vi kan använda listbyggare (list
comprehensions) kan vi använda lexikonbyggare (dict
comprehensions) för att bygga lexikon på ett effektivt sätt!
Exempel:
l = [
['a', '10', '9'],
['C', '-8', '0'],
['P', '4', '2']
]
d = {v[0]: v[1:] for v in l}
print(d)
Ger utskriften
{'a': ['10', '9'], 'C': ['-8', '0'], 'P': ['4', '2']}
Anmärkning 1: När du använder csv-paketet för att läsa en CSV-fil
får värdena typen str. Eftersom det är mätvärden vi har att göra med
är det mycket rimligare att de lagras som typen float för de
beräkningar vi ska göra sedan. Som vi sett tidigare i kursen
går det lätt att konvertera en lista med str-element till en lista med
float-element genom listbyggare eller funktionen map(). Ett
kort exempel:
strList = ['321', '5433', '11']
# Med en listbyggare
floatListComp = [float(s) for s in strList]
# Med funktionen map()
floatListMap = list(map(float, strList))
Anmärkning 2: I filen CO2Emissions_filtered.csv är landskoderna
skrivna med versaler. Eftersom vi vill kombinera informationen från den
här filen med andra data i uppgiften måste de omvandlas till gemener
(små bokstäver). Du kan göra det med funktionen lower(), som förstås
kan användas direkt i en lexikonbyggare. Mer information om
lower() finns t.ex. i den officiella
dokumentationen.
Valfritt: Hela omvandlingen av strängar till flyttal och landskoderna till gemener kan göras på en enda rad direkt när data läses in. På den raden kan det hända att du vill använda både list- och lexikonbyggare.
II. Presentera data#
Matplotlib är den mest populära Pythonmodulen för grundläggande visualisering och plottning. Det finns många olika alternativ. Delar av biblioteket är också gjorda för att likna motsvarande funktioner i Matlab, men de är inte identiska.
Det kan hända att du måste installera den här modulen på din dator.
Här finns
instruktioner för det. matplotlib ingår också i Anacondadistributionen
av Python, så ett sätt är att gå tillbaka till lektion 1 för information
om hur du installerar den. Om du får problem att installera paketet
eller att få det att fungera, se till att be om hjälp under labbarna.
Den finns officiella exempel på hur man kan använda matplotlib
här
och här.
Tvådimensionella data#
Vi börjar med ett enkelt exempel. Du kan provköra det själv för att
se att matplotlib fungerar.
import matplotlib.pyplot as plt
from math import pi, sin
# Data for plotting
L = 100
time = list(range(L))
Voltage = [sin(2*pi*t/L) for t in time]
fig, ax = plt.subplots()
ax.plot(time, Voltage)
ax.set(xlabel='time (s)', ylabel='voltage (mV)', title='Example 1')
ax.grid()
fig.savefig("test.png")
plt.show()
Förklaring rad för rad#
import matplotlib.pyplot as pltimporterar en delmodul imatplotliboch ger den aliasetplt.fig, ax = plt.subplotsskapar figurens ram.ax.plot(time, Voltage)ritar upp de data som tidigare beräknades itimeochVoltage. I detta fall är innehållet listor, men man kan också använda arrayer, som är vanliga i paketetnumpy.ax.set(xlabel='time (s)', ylabel='voltage (mV)', title='Example 1')sätter ut etiketter för de båda axlarna och en rubrik för hela figuren.ax.grid()skapar ett rutnät i figuren, vilket kan göra det lättare att läsa av numeriska värden.fig.savefig("test.png")sparar figuren som en.png-fil med angivet filnamn.Matplotlibstöder flera olika bildformat. Biblioteket stöder både vektorgrafik (som.pdf,.eps,.svg) och bitmappsformat (som.pngoch.jpg). Om man kan välja brukar vektorgrafik ge bättre resultat när figurerna ska visas, särskilt vid utskrifter.plt.show()visar figuren i ett nytt fönster.
Tips! Det vanligaste sättet att lära sig matplotlib är att titta
på exempel som gör liknande saker. Det är viktigt att du försöker titta
på några exempel innan du skriver koden för ditt eget projekt.
Obligatorisk uppgift B#
Använd lexikonet från uppgift A för att ta fram data för de fem nordiska länderna (Danmark, Finland, Island, Norge och Sverige) för åren 1960 till och med 2014. Landskoderna för dessa länder är
'dnk', 'fin', 'isl', 'nor', 'swe'. Tidsintervallet kan skapas som en lista med kommandottime = list(range(1960, 2015)). Om du tittar på data direkt ser du att det finns en del störande variationer, eller brus.Det går att minska bruset genom att använda de två olika medelvärdesfunktionerna från lektion 6,
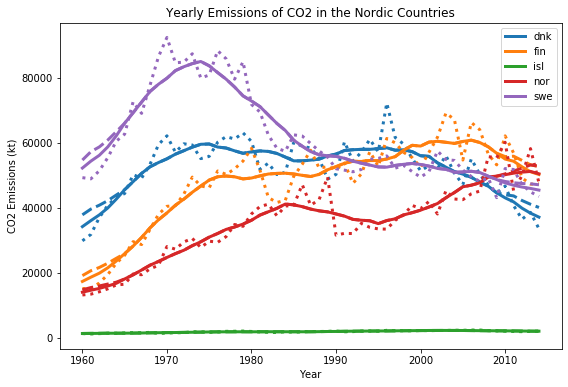
smooth_aochsmooth_b. Användsmooth_aochsmooth_bför att jämna ut data över en total period om 11 år, det vill säga 5 datapunkter ytterligare runt ett mittår. Illustrera resultaten frånsmooth_amed heldragen kurva,smooth_bmed streckad kurva och ursprungsdata med prickad kurva, för alla fem länderna. Du ska alltså totalt plotta 15 dataset. Se till att inte duplicera kod i onödan! Använd en färg per land för att skilja dem åt, men låt alla kurvor för samma land använda en och samma färg. Nedan visas ett exempel på hur resultaten kan se ut, men välj själv vilket exakt utseende du tycker blir bäst så länge du följer ovanstående krav.
Visualisera data med mer än två dimensioner#
Om man har data med mer än två dimensioner kan de ibland ändå visualieras effektivt genom att använda punkter med två rumsliga dimensioner och sedan låta attribut för punkterna (t.ex. färg eller radie) förmedla ytterligare information. Nedan finns ett kort exempel:
import matplotlib.pyplot as plt
import random
random.seed(20191126)
fig, ax = plt.subplots(figsize=(6, 6))
N = 50
for color in ['tab:blue', 'tab:orange', 'tab:green']:
x = [200**random.random() for i in range(N)]
y = [200**random.random() for i in range(N)]
scale = [500*random.random() for i in range(N)]
ax.scatter(x, y, s=scale, c=color, label=color,
alpha=0.3, edgecolors='none')
ax.legend()
plt.show()
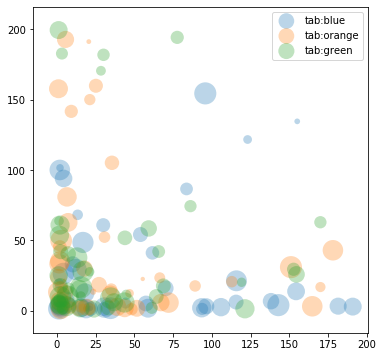
Om man ser till datasetet i sin helhet finns fyra dimensioner:
x-koordinat, y-koordinat, color och scale. Koordinaterna har
slumpats enligt en likformig fördelning mellan 0 och 200. Storleken på
varje punkt har slumpats likformigt mellan 0 och 500.
ax.scatter(x, y, c=color, s=scale, label=color, alpha=0.3, edgecolors='none')
är kärnpunkten i exemplet. Kommandot tar x- och y-koordinater som de
två första argumenten. Dessutom används namngivna argument för att
meddela color (parametern c) och scale (parametern s).
Argumentet alpha, som är ett värde mellan 0 och 1, styr
genomskinlighet. De första värdena i listorna x och y ritas först
och täcks sedan successivt av senare värden.
Frivilliga uppgifter#
Ladda ner filen population.csv. Använd funktionen
load_csv()som du skrev tidigare för att importera dina data. Som en enkel kontroll för att se att allt fungerar plottar du befolkningen i Bolivia, Venezuela, Chile, Ecuador och Paraguay. Se till att det finns x- och y-etiketter i figuren och att figuren har både rubrik och teckenförklaring.Det är vanligt att man vill kombinera data från flera olika källor. Det kan innebära att data finns i olika format, eller att det inte finns ett totalt överlapp mellan olika uppgifter så att vissa element saknas. I så fall kan man behöva formatera om sina data. I det här fallet förhåller det sig så att dataseten från
CO2Emissions_filtered.csvochpopulation.csvinte innehåller exakt samma länder (vissa länder saknas från det första datasetet för att data saknas för hela perioden 1960-2014). Skriv en funktionintersection(list_1, list_2). Funktionen ska ta in två listor med landskoder och returnera en ny lista som bara innehåller de koder som finns i bådelist_1ochlist_2.Exempel: Om man anropar funktionen på följande sätt
intersection(['fra', 'deu', 'ita', 'nld', 'lux'], ['bel', 'ita', 'fra', 'nld'])
ska denna lista retuneras:
['fra', 'ita', 'nld']
Skapa en scatterplot med CO2-utsläpp avsatta mot befolkning för år 2014. Ta med alla länder som finns i båda dataseten. (Det bör bli 141 länder.)
Använd en
log-log-skala i figuren för att den ska bli tydligare. Se till att ha med x- och y-etiketter och diagramrubrik. Lägg till textförklaring med landskod för varje punkt. Ett exempel på hur figuren kan se ut visas nedan.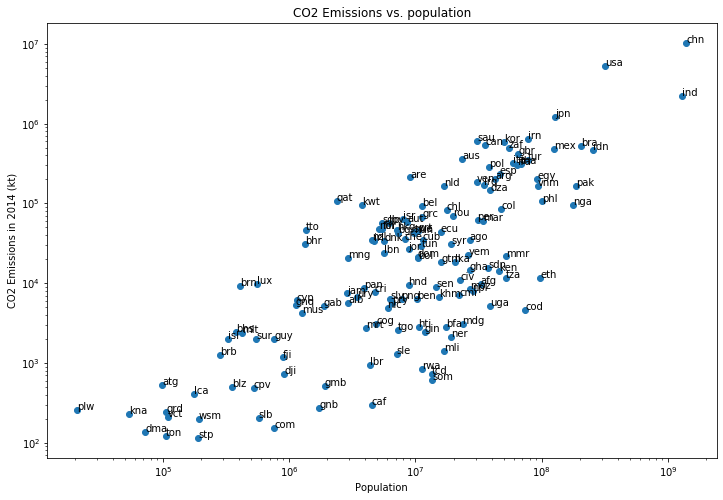
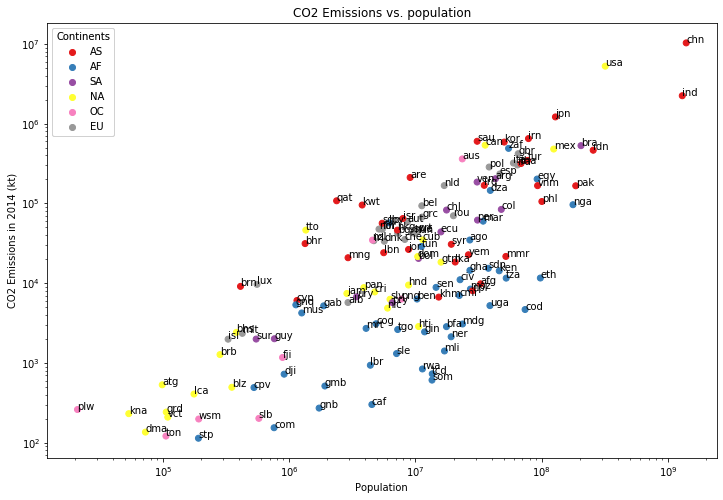
Även om figuren ovan visar en trend kan man vilja förmedla mer information. Det kan till exempel säga en del att färgmarkera länderna efter kontinent. Det finns kontinentkoder i datafilen country_continent.csv. Nedan visas ett exempel på hur figuren kan se ut då.
Det finns massor med möjligheter! Det går till exempel att ge varje punkt en färg efter förändringen (positiva värden för ökning) i CO2-utsläpp mellan 1994 och 2014. Vi föreslår att du använder färgschemat (color map)
coolwarm). Eftersom vissa länder (till exempel Kina, USA och Indien) har ökat sitt utsläpp avsevärt mycket mer än andra, är det svårt att se skillnaderna mellan de övriga länderna.scatterkan ta två valfria argument som sätter gränserna i färgschemat; alltsåvminochvmax. Justera färgschemat för att fixa detta. Ett exempel på hur figuren skulle kunna se ut visas nedan.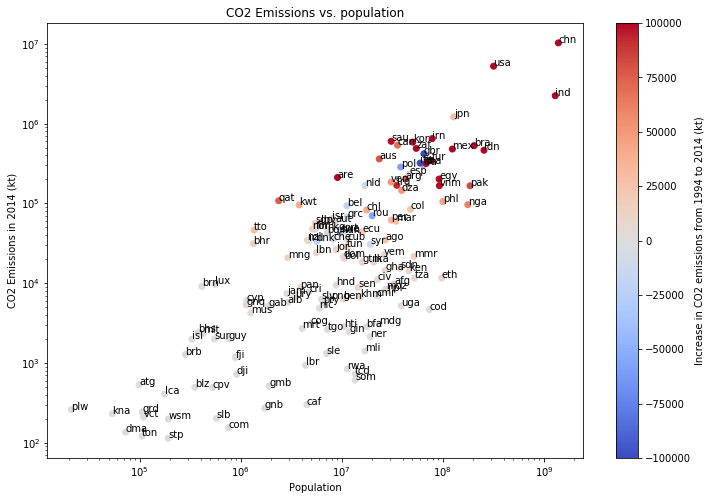
De data som använts i lektionen har hämtats från Världsbanken och Gapminder. Det finns mängder av öppna dataset hos båda dessa källor. Titta gärna vidare själv!